


 50010702506256
50010702506256


 分类:
Python
分类:
Python
开坑
年关将近,终于对12306下手了,,
平安夜撸代码,攻克了12306的登陆 2018-12-24 22:16:00
2018-12-24 22:16:00
没错 这篇博客就写从零开始的异世界..(误) 一从零开始的抢票
可能为期比较长 毕竟下班了才有时间写.. 也才接触python半年不到 所以也是一边学习一边写的比较慢...
一、登陆
采用扫码二维码的方式登陆,就是得下个app。。 验证码太烦了,不想搞
1.获取二维码:
先分析二维码一般是一张图片,我们把他下载到本地 来方便扫码
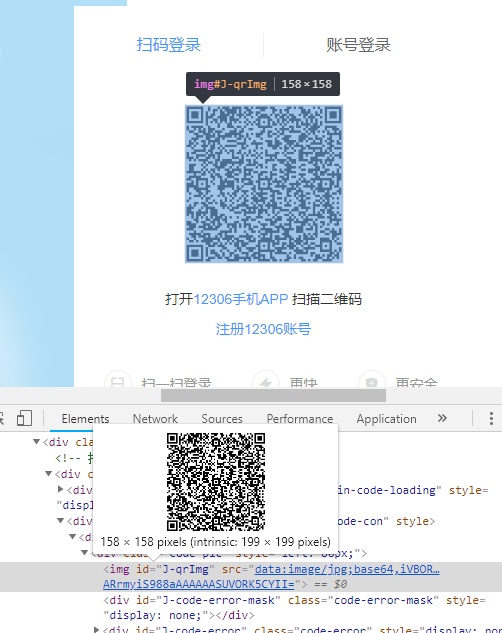
图片还是base64的数据形式
但是我们用传统的方式爬下来 并不能取到图片的信息,只有一个图片占位标签
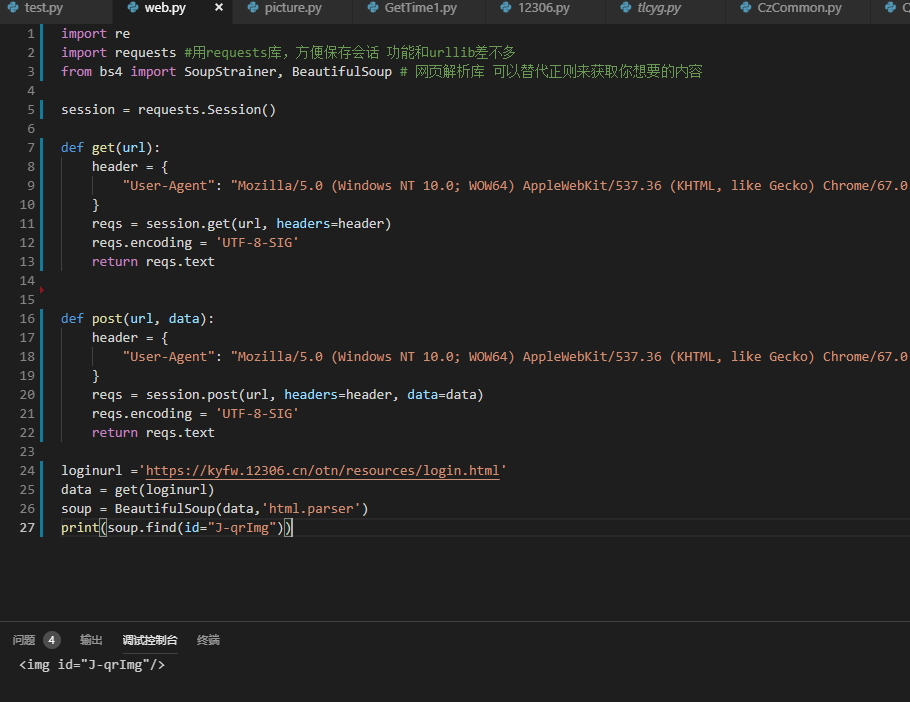
拿到的东西没有src内容 但是页面上却有,说明图片的url是动态获取填充的
(用到了 SoupStrainer 库安装pip install beautifulSoup4,介绍:开坑中 )
继续分析,发现有这样一个请求,可以拿到图片的src内容

图片是base64形式存储的 可以直接把他保存为图片 (base64:二进制编码数据形式,图片存数据库一般就这样放,取出来解析就是一张图,但是一般会比较长。。 )
需要用到一个库操作图片pip install pillow
由于图片是base64 还需要引入base64的库解码
模拟请求,下载图片:
地址:https://kyfw.12306.cn/passport/web/create-qr64
参数:{appid:otn} //固定的
返回:
{"result_message":"生成二维码成功","result_code":"0","image":"iVBORw0KGgoAAAANSUhEUgAAAMcAAA......","uuid":"4B-aKlPZTyR4xlPGh7wmTz553-0ep8w-Lufw8sVxCir-mcQuzTf9iZPX-M4OZYBWjRiASiGJaiv0we1"}代码:
import base64
import json
import os
import re
import requests # 用requests库,方便保存会话 功能和urllib差不多
from bs4 import BeautifulSoup, SoupStrainer # 网页解析库 可以替代正则来获取你想要的内容
from PIL import Image # 操作图片
session = requests.Session() # session会话对象,请求和返回的信息保存在session中
def get(url):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
reqs = session.get(url, headers=header)
return reqs.text
def post(url, data):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
reqs = session.post(url, headers=header, data=data)
return reqs.text
#获取二维码图片
def getQR():
data = post(
'https://kyfw.12306.cn/passport/web/create-qr64', {"appid": "otn"})
json_result = json.loads(data) # 是json格式 直接转成json方便操作
print(json_result)
if(json_result['result_code'] == "0"):
login_pic =getImage(base64.b64decode(json_result['image']))
Image.open(login_pic).show() #依赖PIL库,打开图片(会创建一个零食文件打开图片,图片未被占用时销毁)
def getImage(img):
filepath = './login.png'
with open(filepath, 'wb') as fd: #w写入 b二进制形式
fd.write(img)
return filepath
if __name__ == "__main__":
getQR()结果

搞定 图片拿回来了。
2.登陆扫码
图片是拿回来了也可以扫了,然而扫完之后并没有什么反应啊。。
继续分析! 12306是如何知道我们已经扫码了?
在上一步我们分析拿二维码的时候 应该有注意到,请求中不止一个二维码的,还有一个大概每秒一个的请求
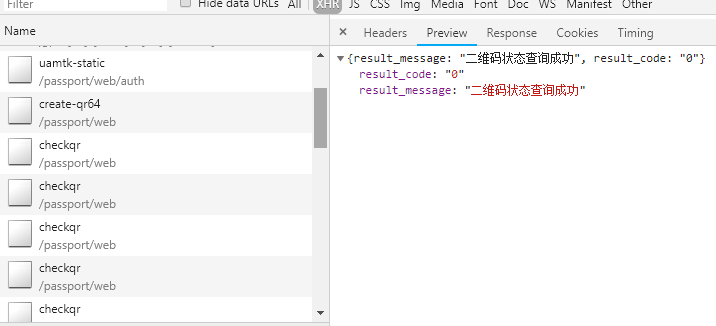
就是这个checkqr根据字面意思,检查二维码!!

我们扫一扫二维码 再看返回内容 注意result_code从0变成了1 !!
点击确定登陆再看(勾上preserve log 不然跳转了日志就没了)
 ??
??
chrome的弊端。。 看不了了 可以用火狐看

搞定! result_code为 2时,说明扫码成功,token get√!!
用程序来模拟这个请求:
地址:https://kyfw.12306.cn/passport/web/checkqr
参数:{
uuid:"", //这个参数在前面取二维码时,有同时返回回来的
appid:otn 固定的
}
返回:
{'result_message': '扫码登录成功', 'result_code': '2', 'uamtk': '1bzmt2A2uZNXk96zw1kwAypjB4m3DzjQease2oBSTCYjnq2q0'}代码:
import base64
import json
import os
import re
import time
import requests # 用requests库,方便保存会话 功能和urllib差不多
from bs4 import BeautifulSoup, SoupStrainer # 网页解析库 可以替代正则来获取你想要的内容
from PIL import Image # 操作图片
import threading
session = requests.Session() # session会话对象,请求和返回的信息保存在session中
def get(url):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
reqs = session.get(url, headers=header)
return reqs.text
def post(url, data):
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
}
reqs = session.post(url, headers=header, data=data)
return reqs.text
# 获取二维码图片
def getQR():
data = post(
'https://kyfw.12306.cn/passport/web/create-qr64', {"appid": "otn"})
json_result = json.loads(data) # 是json格式 直接转成json方便操作
if(json_result['result_code'] == "0"):
uuid = json_result['uuid']
threading._start_new_thread(checkqr,(uuid,)) # 开一个线程去执行监听
login_pic = getImage(base64.b64decode(json_result['image']))
Image.open(login_pic).show() # 依赖PIL库,打开图片(会创建一个零食文件打开图片,图片未被占用时销毁)
def getImage(img):
filepath = './login.png'
with open(filepath, 'wb') as fd: # w写入 b二进制形式
fd.write(img)
return filepath
def checkqr(uuid):
while(True):
checkqr_url = 'https://kyfw.12306.cn/passport/web/checkqr'
data = post(checkqr_url, {"uuid": uuid, "appid": "otn"})
json_result = json.loads(data)
print(json_result)
status_code = json_result['result_code']
if(status_code == "1"):
print('已扫描请确定')
elif(status_code == "2"):
print(json_result['result_message'])
return
elif(status_code == '3'): # 二维码过期
getQR()
return
time.sleep(2)
if __name__ == "__main__":
getQR()结果
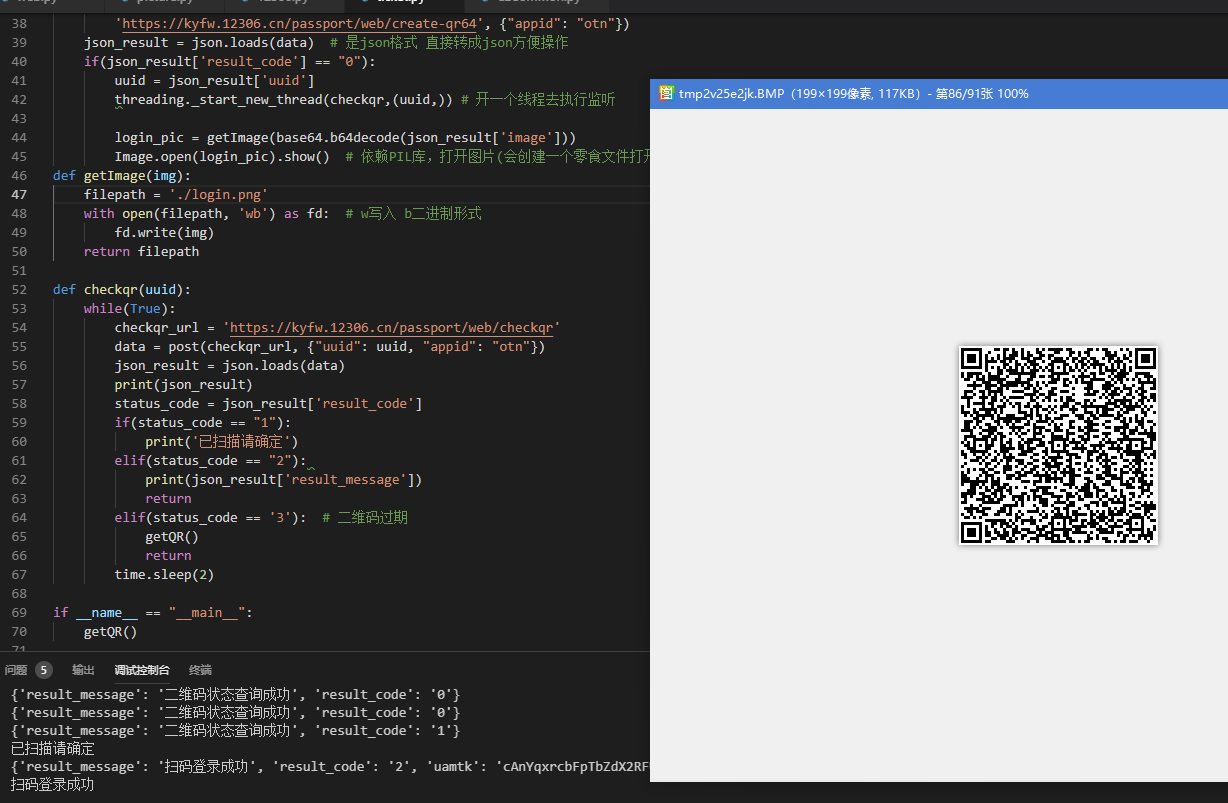
虽然提示扫码登陆成功,现在调用检查是否登陆 可以看到结果flag是false 代表未登录 ↓
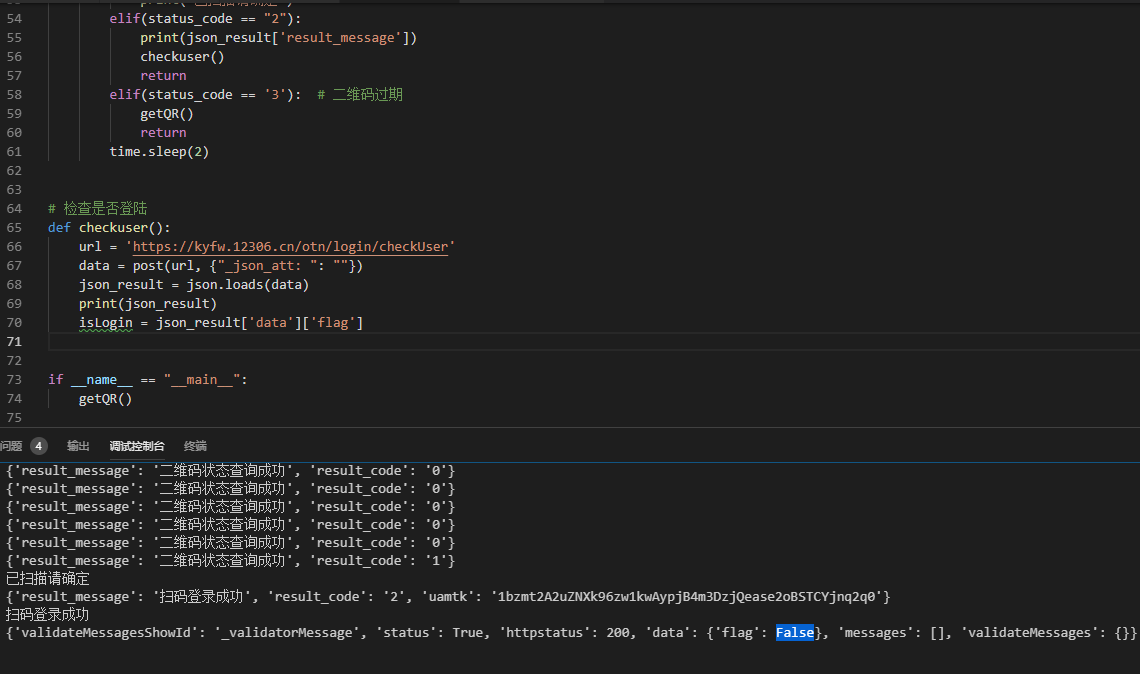
(不贴完整代码了 太长,后面给源码)
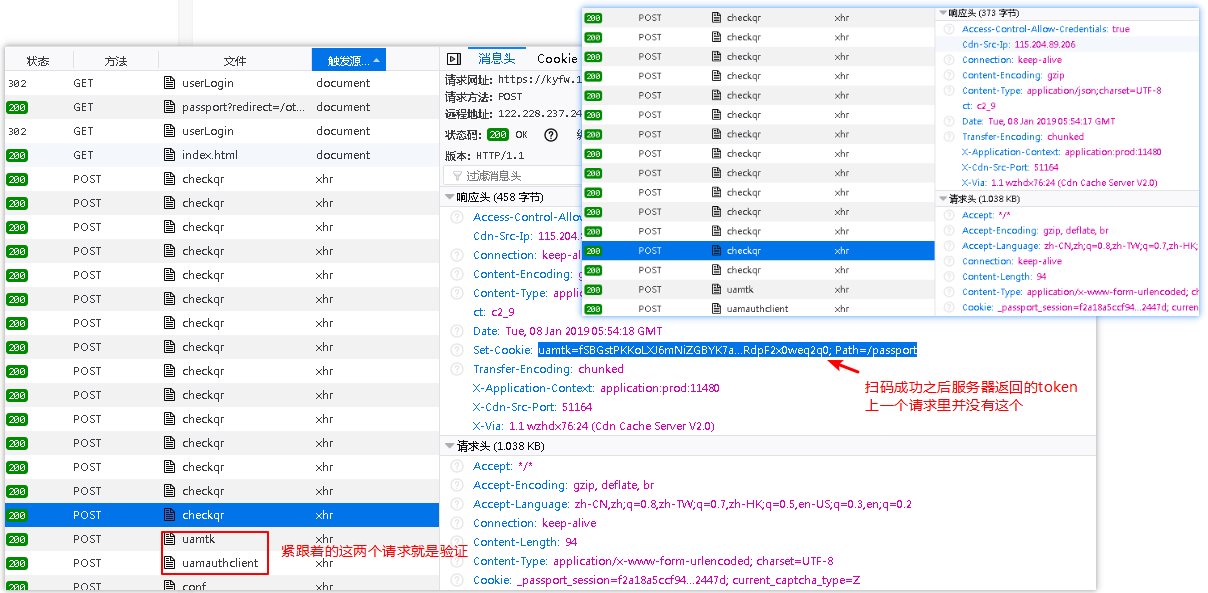
扫码登陆成功主要是取回token,然后带着token去请求验证,可以看到上一个不是扫码成功的请求里并没有token
这里有个重要的点!!!,怎么保存会话 
我们的请求全是通过seeesion来发起的,所有如果请求后返回的信息如token,cookie之类,会自动记录到session中,你再用session来发起时 会自动带上请求的cookie之类的信息!
强大 !
!
验证:
地址:https://kyfw.12306.cn/passport/web/auth/uamtk
参数:{appid:otn} //固定的
返回:
{"result_message":"验证通过","result_code":0,"apptk":null,"newapptk":"oIxLeXFNNYv1526TDD6Avm-oX3OAmexpa3T6bKVEefg36q2q0"}地址:https://kyfw.12306.cn/otn/uamauthclient
参数:{tk:""} //验证1里返回的newapptk
返回:
{"apptk":"oIxLeXFNNYv1526TDD6Avm-oX3OAmexpa3T6bKVEefg36q2q0","result_code":0,"result_message":"验证通过","username":"XX"}模拟请求:
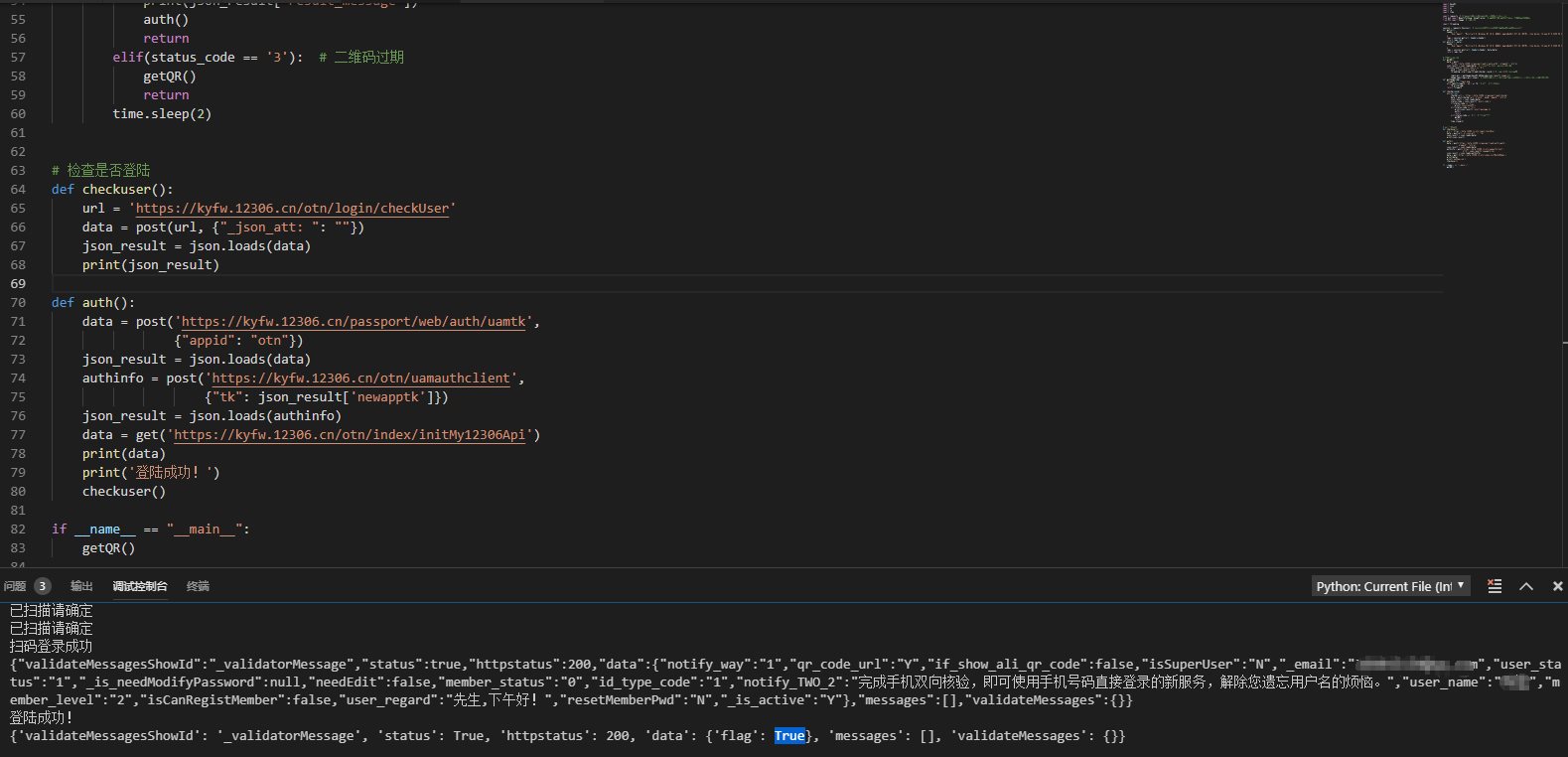
可以看到验证成功之后 返回了你的邮箱或者姓名之类的信息! 再检查是否登陆 flag:Ture!
 到此为止 登陆搞定! 算是剥去衣服
到此为止 登陆搞定! 算是剥去衣服
代码 https://github.com/YuChenDayCode/Ticket/blob/login/ticket.py
整理下流程:
https://kyfw.12306.cn/passport/web/create-qr64 //获取二维码 https://kyfw.12306.cn/passport/web/checkqr //检查二维码是否过期或是否被扫码 https://kyfw.12306.cn/passport/web/auth/uamtk //验证 https://kyfw.12306.cn/otn/uamauthclient //二次验证
下一步刷票 http://www.tnblog.net/cz/article/details/241
欢迎加群讨论技术,1群:677373950(满了,可以加,但通过不了),2群:656732739